Control Node replacement on Openshift 4 for AssistedInstaller!
In the following post, we are going to talk on how to perform a node replacement (control node) of OCPv4.10.X.
Prerequisites
- OCPv4.10.X installed using AssistedInstaller.
- skopeo cli available.
- podman cli available. For more information on how to install container tools.
- internet connection (through a proxy).
Step 0. How to mirror the quay.io container base images to the offline registry
The list of the used container based images in this tutorial are:
quay.io/centos7/httpd-24-centos7:latest
quay.io/coreos/butane:release
quay.io/coreos/coreos-installer:releaseIn order to mirror those images to the offline registry:
skopeo copy docker://quay.io/centos7/httpd-24-centos7:latest docker://INBACRNRDL0100.offline.oxtechnix.lan:5000/centos7/httpd-24-centos7:latest --dest-tls-verify=falseValidating that the image its available on the offline registry:
curl -X GET -u <username>:<password> https://INBACRNRDL0100.offline.oxtechnix.lan:5000/v2/_catalog --insecure | jq .
{
"repositories": [
"centos7/httpd-24-centos7"
]
}skopeo copy docker://quay.io/coreos/butane:release docker://INBACRNRDL0100.offline.oxtechnix.lan:5000/coreos/butane:release --dest-tls-verify=falseValidating that the image its available on the offline registry:
curl -X GET -u <username>:<password> https://INBACRNRDL0100.offline.oxtechnix.lan:5000/v2/_catalog --insecure | jq .
{
"repositories": [
"coreos/butane"
]
}skopeo copy docker://quay.io/coreos/coreos-installer:release docker://INBACRNRDL0100.offline.oxtechnix.lan:5000/coreos/coreos-installer:release --dest-tls-verify=falseValidating that the image its available on the offline registry:
curl -X GET -u <username>:<password> https://INBACRNRDL0100.offline.oxtechnix.lan:5000/v2/_catalog --insecure | jq .
{
"repositories": [
"coreos/coreos-installer"
]
}If this step its implemented, you will need on further steps to replace the quay.io/centos7/ with INBACRNRDL0100.offline.oxtechnix.lan:5000/centos7/ and quay.io/coreos/ with INBACRNRDL0100.offline.oxtechnix.lan:5000/coreos/ in order to use the offline registry as a source and not the public registry.
Step 1. How to change the state of the nodes after the Assisted Installer finished
Those operations are required to be performed as a DAY2Operation to bring the BareMetalHost object status of each nodes of the OCPv4.10 cluster from unmanaged to externally provisioned. This section has been added here with the purpose of highlighting that in case one of the controller node its required to be replaced soon after the OCP cluster installation ended, you will need to consider this step.
To highlight this, we are going to use a compact cluster (3 control nodes + 0 worker nodes).
oc get nodes
NAME STATUS ROLES AGE VERSION
cu-master1 Ready master,worker 138m v1.23.5+012e945
cu-master2 Ready master,worker 152m v1.23.5+012e945
cu-master3 Ready master,worker 159m v1.23.5+012e945The BMH object status:
oc get bmh -n openshift-machine-api
NAME STATE CONSUMER ONLINE ERROR AGE
cu-master1 unmanaged test-cluster-xkmdh-master-0 true 3h12m
cu-master2 unmanaged test-cluster-xkmdh-master-1 true 3h12m
cu-master3 unmanaged test-cluster-xkmdh-master-2 true 3h12mAs you can observe in the above BMH object the STATE of each node its in the unmanaged, we will have to update this object to be managed in order to have the cluster ready for the node replacement.
We will have to create the secret and update the address, credentialsName and set disableCertificateVerification: true for each individual nodes.
- cu-master1:
---
apiVersion: v1
data:
password: Y2Fsdmlu
username: cm9vdA==
kind: Secret
metadata:
name: cu-master1-bmc-secret
namespace: openshift-machine-api
type: Opaque
---
apiVersion: metal3.io/v1alpha1
kind: BareMetalHost
metadata:
name: cu-master1
namespace: openshift-machine-api
spec:
automatedCleaningMode: metadata
bmc:
address: idrac-virtualmedia://192.168.34.230/redfish/v1/Systems/System.Embedded.1
credentialsName: cu-master1-bmc-secret
disableCertificateVerification: true
bootMACAddress: b0:7b:25:d4:e8:20
bootMode: UEFI
online: true- cu-master2:
---
apiVersion: v1
data:
password: Y2Fsdmlu
username: cm9vdA==
kind: Secret
metadata:
name: cu-master2-bmc-secret
namespace: openshift-machine-api
type: Opaque
---
apiVersion: metal3.io/v1alpha1
kind: BareMetalHost
metadata:
name: cu-master2
namespace: openshift-machine-api
spec:
automatedCleaningMode: metadata
bmc:
address: idrac-virtualmedia://192.168.34.231/redfish/v1/Systems/System.Embedded.1
credentialsName: cu-master3-bmc-secret
disableCertificateVerification: true
bootMACAddress: b0:7b:25:dd:ce:be
bootMode: UEFI
online: true- cu-master3:
---
apiVersion: v1
data:
password: Y2Fsdmlu
username: cm9vdA==
kind: Secret
metadata:
name: cu-master3-bmc-secret
namespace: openshift-machine-api
type: Opaque
---
apiVersion: metal3.io/v1alpha1
kind: BareMetalHost
metadata:
name: cu-master3
namespace: openshift-machine-api
spec:
automatedCleaningMode: metadata
bmc:
address: idrac-virtualmedia://192.168.34.232/redfish/v1/Systems/System.Embedded.1
credentialsName: cu-master3-bmc-secret
disableCertificateVerification: true
bootMACAddress: b0:7b:25:d4:59:80
bootMode: UEFI
online: trueNOTE: In the above example, the the Hardware type its very important:
- for DELL servers on the
addressits usedidrac-virtualmedia://ip_address_of_the_bmh_interface/redfish/v1/Systems/System.Embedded.1 - for HPE servers on the
addressits usedredfish-virtualmedia://ip_address_of_the_bmh_interface/redfish/v1/Systems/1
For more information on its available on Redhat official documentation page.
Apply the objects for each nodes:
oc apply -f update-masterX-bmh.yaml
secret/cu-masterX-bmc-secret created
Warning: resource baremetalhosts/cu-masterX is missing the kubectl.kubernetes.io/last-applied-configuration annotation which is required by oc apply. oc apply should only be used on resources created declaratively by either oc create --save-config or oc apply. The missing annotation will be patched automatically.
baremetalhost.metal3.io/cu-masterX configured- Verify that the secrets associated to each node has been created:
oc get secrets -n openshift-machine-api
NAME TYPE DATA AGE
...
cu-master1-bmc-secret Opaque 2 104m
cu-master2-bmc-secret Opaque 2 102m
cu-master3-bmc-secret Opaque 2 15s
...- Verify that the BMH object state has been updated:
oc get bmh -n openshift-machine-api
NAME STATE CONSUMER ONLINE ERROR AGE
cu-master1 externally provisioned test-cluster-xkmdh-master-0 true 3h25m
cu-master2 externally provisioned test-cluster-xkmdh-master-1 true 3h25m
cu-master3 externally provisioned test-cluster-xkmdh-master-2 true 3h25mOnce those steps are fully completed without errors, you can proceed further on the cluster usage.
Step 2. ETCD cluster back-up procedure
For more informations regarding the ETCD cluster back-up procedure from Redhat.
Please, note that the ETCD cluster back-up can be proceed when the cluster is healthy and also when one of the node is been lost. In the following example, we are going to cover when one of the node has been lost, but the steps wont be changed in the other scenario.
Display the nodes in the cluster:
oc get nodes
NAME STATUS ROLES AGE VERSION
kni1-master-0.cloud.lab.eng.bos.redhat.com Ready master,worker 8d v1.21.11+6b3cbdd
kni1-master-1.cloud.lab.eng.bos.redhat.com Ready master,worker 8d v1.21.11+6b3cbdd
kni1-master-2.cloud.lab.eng.bos.redhat.com NotReady master,worker 99m v1.21.11+6b3cbddConnect to one of the nodes in the cluster:
oc debug node/kni1-master-0.cloud.lab.eng.bos.redhat.com
Starting pod/kni1-master-0cloudlabengbosredhatcom-debug ...
To use host binaries, run `chroot /host`
Pod IP: 10.19.138.11
If you don't see a command prompt, try pressing enter.
sh-4.4#
sh-4.4#
sh-4.4# chroot /host
sh-4.4# /bin/bash
[systemd]
Failed Units: 1
NetworkManager-wait-online.service
[root@kni1-master-0 /]#At this point we can run the back-up script available on the node:
[root@kni1-master-0 /]# /usr/local/bin/cluster-backup.sh /home/core/assets/backup
found latest kube-apiserver: /etc/kubernetes/static-pod-resources/kube-apiserver-pod-15
found latest kube-controller-manager: /etc/kubernetes/static-pod-resources/kube-controller-manager-pod-9
found latest kube-scheduler: /etc/kubernetes/static-pod-resources/kube-scheduler-pod-8
found latest etcd: /etc/kubernetes/static-pod-resources/etcd-pod-11
2355b836ed2da7166a4deada628681d110131ccf58e6695e30a2e005a075d041
etcdctl version: 3.4.14
API version: 3.4
{"level":"info","ts":1654790640.5072594,"caller":"snapshot/v3_snapshot.go:119","msg":"created temporary db file","path":"/home/core/assets/backup/snapshot_2022-06-09_160359.db.part"}
{"level":"info","ts":"2022-06-09T16:04:00.515Z","caller":"clientv3/maintenance.go:200","msg":"opened snapshot stream; downloading"}
{"level":"info","ts":1654790640.515958,"caller":"snapshot/v3_snapshot.go:127","msg":"fetching snapshot","endpoint":"https://10.19.138.13:2379"}
{"level":"info","ts":"2022-06-09T16:04:01.395Z","caller":"clientv3/maintenance.go:208","msg":"completed snapshot read; closing"}
{"level":"info","ts":1654790641.4325762,"caller":"snapshot/v3_snapshot.go:142","msg":"fetched snapshot","endpoint":"https://10.19.138.13:2379","size":"138 MB","took":0.925249543}
{"level":"info","ts":1654790641.4326785,"caller":"snapshot/v3_snapshot.go:152","msg":"saved","path":"/home/core/assets/backup/snapshot_2022-06-09_160359.db"}
Snapshot saved at /home/core/assets/backup/snapshot_2022-06-09_160359.db
{"hash":2784831220,"revision":9953578,"totalKey":14626,"totalSize":137506816}
snapshot db and kube resources are successfully saved to /home/core/assets/backupValidating that the backup files have been created and they do exist:
[root@kni1-master-0 /]# ls -l /home/core/assets/backup/
total 134364
-rw-------. 1 root root 137506848 Jun 9 16:04 snapshot_2022-06-09_160359.db
-rw-------. 1 root root 76154 Jun 9 16:03 static_kuberesources_2022-06-09_160359.tar.gzAt this stage we made sure that we have a current ETCD cluster backup available on a running node, this can be externally exported to your laptop or a external storage for data persistance. In the next steps, we are going to proceed with removing the unhealthy ETCD node in the cluster.
Step 3. Remove unhealthy ETCD cluster member
For more informations regarding the remove of unhealthy ETCD cluster member procedure from Redhat.
oc get nodes
NAME STATUS ROLES AGE VERSION
kni1-master-0.cloud.lab.eng.bos.redhat.com Ready master,worker 8d v1.21.11+6b3cbdd
kni1-master-1.cloud.lab.eng.bos.redhat.com Ready master,worker 8d v1.21.11+6b3cbdd
kni1-master-2.cloud.lab.eng.bos.redhat.com NotReady master,worker 113m v1.21.11+6b3cbddChecking the ETCD pods on the cluster:
oc get pods -n openshift-etcd | grep -v etcd-quorum-guard | grep etcd
etcd-kni1-master-0.cloud.lab.eng.bos.redhat.com 4/4 Running 0 53m
etcd-kni1-master-1.cloud.lab.eng.bos.redhat.com 4/4 Running 0 56m
etcd-kni1-master-2.cloud.lab.eng.bos.redhat.com 4/4 Running 0 56mConnect to the pod that is not assigned of the node with STATUS NotReady:
oc project openshift-etcd
Already on project "openshift-etcd" on server "https://api.kni1.cloud.lab.eng.bos.redhat.com:6443".oc rsh etcd-kni1-master-0.cloud.lab.eng.bos.redhat.com
Defaulted container "etcdctl" out of: etcdctl, etcd, etcd-metrics, etcd-health-monitor, setup (init), etcd-ensure-env-vars (init), etcd-resources-copy (init)
sh-4.4#Check the ETCD member list:
sh-4.4# etcdctl member list -w table
+------------------+---------+--------------------------------------------+---------------------------+---------------------------+------------+
| ID | STATUS | NAME | PEER ADDRS | CLIENT ADDRS | IS LEARNER |
+------------------+---------+--------------------------------------------+---------------------------+---------------------------+------------+
| 5b080c81fee5526d | started | kni1-master-0.cloud.lab.eng.bos.redhat.com | https://10.19.138.11:2380 | https://10.19.138.11:2379 | false |
| a863d615322849cb | started | kni1-master-1.cloud.lab.eng.bos.redhat.com | https://10.19.138.12:2380 | https://10.19.138.12:2379 | false |
| c05aa2adbc319032 | started | kni1-master-2.cloud.lab.eng.bos.redhat.com | https://10.19.138.13:2380 | https://10.19.138.13:2379 | false |
+------------------+---------+--------------------------------------------+---------------------------+---------------------------+------------+
sh-4.4#Take note of the ID and the name of the unhealthy etcd member, because those values are needed later in the procedure.
sh-4.4# etcdctl endpoint health
{"level":"warn","ts":"2022-06-09T16:23:51.165Z","caller":"clientv3/retry_interceptor.go:62","msg":"retrying of unary invoker failed","target":"endpoint://client-1a51aaca-cf9d-4421-855c-fb19cfbfe07d/10.19.138.13:2379","attempt":0,"error":"rpc error: code = DeadlineExceeded desc = latest balancer error: all SubConns are in TransientFailure, latest connection error: connection error: desc = \"transport: Error while dialing dial tcp 10.19.138.13:2379: connect: connection refused\""}
https://10.19.138.11:2379 is healthy: successfully committed proposal: took = 12.718254ms
https://10.19.138.12:2379 is healthy: successfully committed proposal: took = 12.879825ms
https://10.19.138.13:2379 is unhealthy: failed to commit proposal: context deadline exceeded
Error: unhealthy clusterRemove the unhealthy member:
sh-4.4# etcdctl member remove c05aa2adbc319032View the member list again and verify that the member was removed:
sh-4.4# etcdctl member list -w table
+------------------+---------+--------------------------------------------+---------------------------+---------------------------+------------+
| ID | STATUS | NAME | PEER ADDRS | CLIENT ADDRS | IS LEARNER |
+------------------+---------+--------------------------------------------+---------------------------+---------------------------+------------+
| 5b080c81fee5526d | started | kni1-master-0.cloud.lab.eng.bos.redhat.com | https://10.19.138.11:2380 | https://10.19.138.11:2379 | false |
| a863d615322849cb | started | kni1-master-1.cloud.lab.eng.bos.redhat.com | https://10.19.138.12:2380 | https://10.19.138.12:2379 | false |
+------------------+---------+--------------------------------------------+---------------------------+---------------------------+------------+ Once this is validated, please exit the node shell.
Remove the old secrets for the unhealthy etcd member that was removed.
List the secrets for the unhealthy etcd member that was removed:
oc get secrets -n openshift-etcd | grep kni1-master-2.cloud.lab.eng.bos.redhat.com
etcd-peer-kni1-master-2.cloud.lab.eng.bos.redhat.com kubernetes.io/tls 2 81m
etcd-serving-kni1-master-2.cloud.lab.eng.bos.redhat.com kubernetes.io/tls 2 81m
etcd-serving-metrics-kni1-master-2.cloud.lab.eng.bos.redhat.com kubernetes.io/tls 2 81m Force the etcd redeployment:
oc patch etcd cluster -p='{"spec": {"forceRedeploymentReason": "single-master-recovery-'"$( date --rfc-3339=ns )"'"}}' --type=mergeStep 4. Removing the unhealthy control-node
oc get clusteroperator baremetal
NAME VERSION AVAILABLE PROGRESSING DEGRADED SINCE MESSAGE
baremetal 4.10.25 True False False 7h24m Check the BareMetalHost object:
oc get bmh -n openshift-machine-api
NAME STATE CONSUMER ONLINE ERROR AGE
cu-master1 unmanaged example-tz69q-master-0 true 9h
cu-master2 unmanaged example-tz69q-master-1 true 9h
cu-master3 unmanaged example-tz69q-master-2 true 3h30m
hub-node1 unmanaged example-tz69q-worker-0-94mj7 true 9h
hub-node2 unmanaged example-tz69q-worker-0-h754z true 9h
hub-node3 unmanaged example-tz69q-worker-0-njjpv true 9hCheck the Machine Object:
oc get machines -n openshift-machine-api -o wide
NAME PHASE TYPE REGION ZONE AGE NODE PROVIDERID STATE
nokia-example-tz69q-master-0 Running 9h cu-master1 baremetalhost:///openshift-machine-api/cu-master1/c643004b-3646-4eae-8798-346754947a0c unmanaged
nokia-example-tz69q-master-1 Running 9h cu-master2 baremetalhost:///openshift-machine-api/cu-master2/9c8f87a3-108a-4af7-9b0d-adbc122bf616 unmanaged
nokia-example-tz69q-master-2 Provisioned 3h33m cu-master3 baremetalhost:///openshift-machine-api/cu-master3/2c6847d7-cd20-47dd-9023-020c60a8ba59 unmanaged
nokia-example-tz69q-worker-0-94mj7 Running 8h hub-node1 baremetalhost:///openshift-machine-api/hub-node1/41f80b41-c858-4297-94df-d42a127a93ad unmanaged
nokia-example-tz69q-worker-0-h754z Running 8h hub-node2 baremetalhost:///openshift-machine-api/hub-node2/d8efe54b-b0f4-4a7a-9292-faa3109c25be unmanaged
nokia-example-tz69q-worker-0-njjpv Running 8h hub-node3 baremetalhost:///openshift-machine-api/hub-node3/c712a6a8-2945-40dd-902c-232a44d00999 unmanagedRemove the old BareMetalHost:
oc delete bmh -n openshift-machine-api kni1-master-2Remove the old Machine objects:
oc delete machine -n openshift-machine-api kni1-master-2Check the Machine objects status:
oc get machine -n openshift-machine-api
Error from server (InternalError): an error on the server ("") has prevented the request from succeeding (get machines.machine.openshift.io)NOTE: You should wait for 5-10 minutes until the cluster is transioning to a more stable state to proceed further.
Step 5.1. Reinstall of the removed node
In this step, we are covering the use-case in which the removed node its required to be re-installed, this might be the case in the scenario of a total failure of the root disk of the server or the exposed LUN from the Network-Storage its lost. Before proceeding on the removed node, we should download the rhcos-4.10.26-x86_64-live.x86_64.iso. Which will have to be booted to the server virtual-console.
- Upload the downloaded rhcos-4.10.26-x86_64-live.x86_64.iso to the controller node that you want to add to the cluster virtual-console server:
Open the used port on Bastion Host to be used by the service:
sudo firewall-cmd --add-port=9092/tcp --zone=public --permanent
sudo firewall-cmd --reloadCreating the rhcos_image_cache directory to save rhcos-4.10.26-x86_64-live.x86_64.iso and master.ign:
mkdir -p /apps/rhcos_image_cache sudo semanage fcontext -a -t httpd_sys_content_t "/apps/rhcos_image_cache(/.*)?"
sudo restorecon -Rv /apps/rhcos_image_cache/
Relabeled /apps/rhcos_image_cache from unconfined_u:object_r:unlabeled_t:s0 to unconfined_u:object_r:httpd_sys_content_t:s0Downloading the image to the openshift image mirror:
curl https://rhcos.mirror.openshift.com/art/storage/releases/rhcos-4.10/410.84.202208030316-0/x86_64/rhcos-410.84.202208030316-0-live.x86_64.iso --output /apps/rhcos_image_cache/rhcos-4.10.26-x86_64-live.x86_64.isoExport the ignition data from the cluster:
oc extract -n openshift-machine-api secret/master-user-data --keys=userData --to=/apps/rhcos_image_cache/master.ignThe content of the master.ign should follow the output:
{
"ignition":{
"config":{
"merge":[
{
"source":"https://192.168.34.41:22623/config/master",
"verification":{
}
}
],
"replace":{
"verification":{
}
}
},
"proxy":{
},
"security":{
"tls":{
"certificateAuthorities":[
{
"source":"data:text/plain;charset=utf-8;base64,LS0tLS1CRUdJTiBDRVJUSUZJQ0FURS0tLS0tCk1JSURFRENDQWZpZ0F3SUJBZ0lJTCtRc09UelZJSzB3RFFZSktvWklodmNOQVFFTEJRQXdKakVTTUJBR0ExVUUKQ3hNSmIzQmxibk5vYVdaME1SQXdEZ1lEVlFRREV3ZHliMjkwTFdOaE1CNFhEVEl5TURrd05qRXhNVGswTVZvWApEVE15TURrd016RXhNVGswTVZvd0pqRVNNQkFHQTFVRUN4TUpiM0JsYm5Ob2FXWjBNUkF3RGdZRFZRUURFd2R5CmIyOTBMV05oTUlJQklqQU5CZ2txaGtpRzl3MEJBUUVGQUFPQ0FROEFNSUlCQ2dLQ0FRRUFvTHRUS0hqZG5IY3cKNVpjdmw4OEczK0N5OTZSWUpDNFVZVlNkTUl2bzVad0dvc1dMdVJSSUJnRTVWcm96WVo0Q1REREltY1MvOENyQwp5TTdoZ0U1N2JxS09Od0dXWWF4TUIvK1Mvb2NrZU1lcG1uQ3JLODRCQjhySzR2ZmYwam8wR2ZBTm84bGJDZjFaCmlFMi9NL0RBcjBtdlk3OHM3elU0MkVMSDdwRndsY1VOUWg3RW1yaVJPK09ERjVRdCtURGp6TzRLQ2wzYVpKUzcKNnlDdXBsTlVLUHhKTlM1Q2t0T1B5NndYaVRoZW92Rm5heU1qNmdnVE43QzdLSFFVcDc3RFpWaWt4ZWtxSGswUwpVK0xhdTdaMXUxOHA5eFh6dXgyV3FqRXFwNXpjcWtiblAyY1MxRlZqSkk1R2Q0TXNRRjlZWnVZNEl2OGp5QUwzClV5emh1cGdTcFFJREFRQUJvMEl3UURBT0JnTlZIUThCQWY4RUJBTUNBcVF3RHdZRFZSMFRBUUgvQkFVd0F3RUIKL3pBZEJnTlZIUTRFRmdRVWtiaE1aZGVBSmpvVjJjV0F3dFh1ZTYvUTkvTXdEUVlKS29aSWh2Y05BUUVMQlFBRApnZ0VCQUJHc2xHdnBBWmwzbCtIQTFvclFhUWdZZ1VpQ2NldHkzS1lEUXN4c2YrTUNTWWRKYnptQllBaGNBZHFyCnJYckxWMXhKeWZZbmlUdjBZTHRweVFUUTlFajZBc1dCak9odXovbnV0MFY0d0lZSEJwRUF3MGtzL1ZxbUIvbDUKc09DeDB0Wi9HSERtcys0SEM2VS9wd2o4TUNYcjd0VWZXRExtdnd0NGFFZ1F3MWtGeG9xOTVSVThkWFowM1pGSgpJUWZHemNEOUNXUEJxcmNUcWVWbXA2T1plM2ppSjBZUCtOZDVJTWFHQTFIY2JYTjJsdTllUVZ1a2E2Q3NwT1JNCmZGeVlrZk05Z0VmQlJHemZzWjM4eFFERVZObU91K1VLTVdMOG1rcHVGQTEyZGw0bVhrTWZrT3doZkxTcXVlRGsKNldEWlNBVStzZlppbVZ3aTVTYnphbU5MMWljPQotLS0tLUVORCBDRVJUSUZJQ0FURS0tLS0tCg==",
"verification":{
}
}
]
}
},
"timeouts":{
},
"version":"3.2.0"
},
"passwd":{
},
"storage":{
"files":[
{
"path":"/etc/hostname",
"contents":{
"source":"data:,cu-master3"
},
"mode":420
}
]
},
"systemd":{
}
}Running the podman service that is exposing the files for further use:
podman run -d --name rhcos_image_cache -v /apps/rhcos_image_cache:/var/www/html -p 9092:8080/tcp quay.io/centos7/httpd-24-centos7:latest- Boot the node using the
Virtual CD/DVD/ISOboot mode and boot with it.
Once the right booting control has been chosen you will be able to see in your virtual console the following:
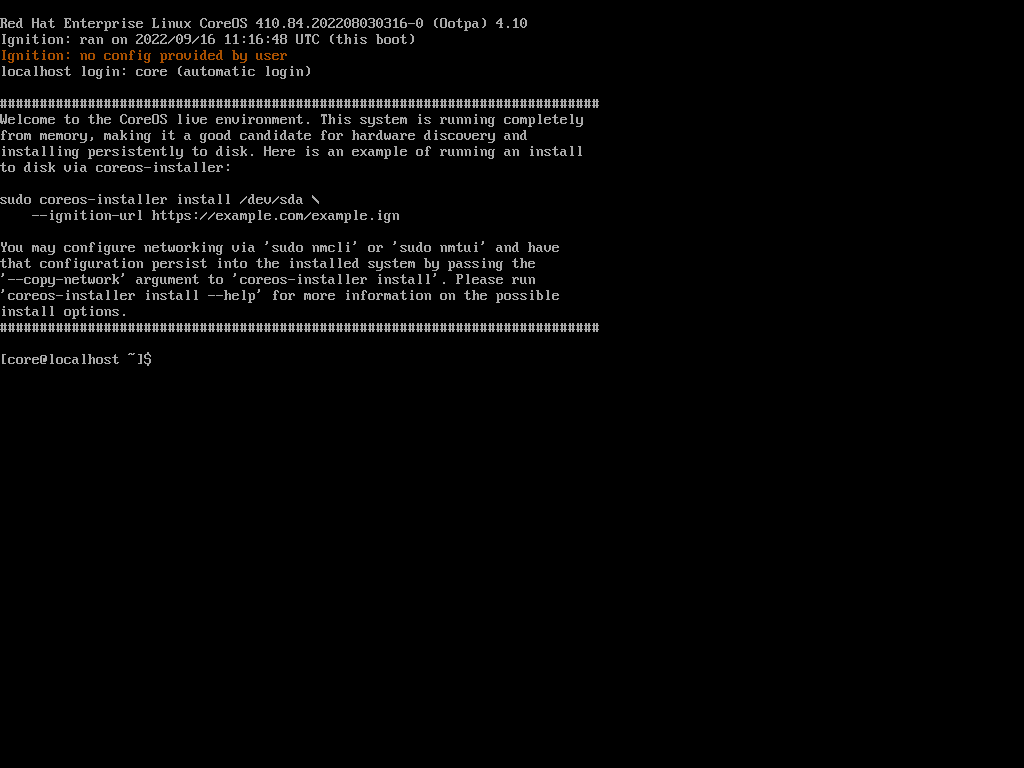
In this example the RHCOS image its Red Hat Enterprise Linux CoreOS 410.84.202208030316-0 (Ootpa) 4.10, this represents an indicator of the image that its usind in the procedure.
- Once the RHCOS booted up, you will need to define the
baremetalinterface: NOTE: In case you are using a different network configuration you will need to adapt it to reflect your environment. The below its a example that reflects the configuration on the test cluster.
Configuring an ethernet connection of the node:
sudo nmcli connection show
sudo nmcli con mod "eno12399" ipv4.addresses "192.168.34.53/25"
sudo nmcli con mod "eno12399" ipv4.method manual
sudo nmcli con mod "eno12399" ipv4.gateway 192.168.34.1
sudo nmcli con mod "eno12399" ipv4.dns 192.168.34.20
sudo nmcli con up "eno12399"In case you are using a bonding configuration on your cluster, check more details here.
Configuring an bond mode 1 connection of the node:
sudo nmcli connection show
sudo nmcli connection add type bond ifname bond0 mode 1
sudo nmcli connection add type bond-slave ifname eno1 master bond0
sudo nmcli connection add type bond-slave ifname eno2 master bond0Configuring an bond mode 4 connection of the node:
sudo nmcli connection show
sudo nmcli connection add type bond ifname bond0 mode 4
sudo nmcli connection add type bond-slave ifname eno1 master bond0
sudo nmcli connection add type bond-slave ifname eno2 master bond0For both situation of monding above the administrator needs to configure the IP address of the bond0 interface:
sudo nmcli con mod "bond0" ipv4.addresses "192.168.34.53/25"
sudo nmcli con mod "bond0" ipv4.method manual
sudo nmcli con mod "bond0" ipv4.gateway 192.168.34.1
sudo nmcli con mod "bond0" ipv4.dns 192.168.34.20
sudo nmcli con up "bond0"- In the case you are using a root disk over SAN with multipath:
sudo modprobe dm-multipath
sudo modprobe dm-round-robin
sudo multipathd -v0
sudo mpathconf --enable
sudo systemctl restart multipathd.service
sudo multipath -ll- Validate that your LUN disks are available:
sudo multipath -llNOTE: The multipathd.service its enabled only for the time until the next reboot has been issued. In order to enable the multipath permanent for iscsi, if you want to enable multipath in ocp.
- Start the installation of the RHCOS to the selected root disk:
sudo coreos-installer install /dev/sdb --ignition-url http://192.168.34.20:9092/discovery/master.ign --insecure-ignition --copy-networkIf you are using a multipath root disk over SAN you will need to install the RHCOS:
sudo coreos-installer install /dev/dm-0 --append-karg rd.multipath=default --append-karg root=/dev/disk/by-label/dm-mpath-root --append-karg=rw --ignition-url http://192.168.34.20:9092/discovery/master.ign --insecure-ignition --copy-networkNOTE: This proses will take some time until its finished, once this its finished the node will reboot and boot using the root disk.
Step 5.2. Reinstall of the removed node by building the RHCOS
In the Step5.1 we introduced the procedure of reinstalling of the removed node in a more decoupled manner. The purpose of the Step5.2 its to centralized all the customisations pre-mounting the iso to the virtual-console of the server.
- On the ProvisioningNode we will need to create the directory for each OCP node:
mkdir -p /apps/rhcos_image_cache/{cu-master1,cu-master2,cu-master3,hub-node1,hub-node2,hub-node3} sudo semanage fcontext -a -t httpd_sys_content_t "/apps/rhcos_image_cache(/.*)?"
sudo restorecon -Rv /apps/rhcos_image_cache/
Relabeled /apps/rhcos_image_cache from unconfined_u:object_r:unlabeled_t:s0 to unconfined_u:object_r:httpd_sys_content_t:s0- Downloading the image to the openshift image mirror:
curl https://rhcos.mirror.openshift.com/art/storage/releases/rhcos-4.10/410.84.202208030316-0/x86_64/rhcos-410.84.202208030316-0-live.x86_64.iso --output /apps/rhcos_image_cache/rhcos-4.10.26-x86_64-live.x86_64.iso- Directory structure:
tree /apps/rhcos_image_cache/
/apps/rhcos_image_cache/
├── cu-master1
│ ├── custom.ign
│ ├── network.ign
│ └── network.bu
├── cu-master2
│ ├── custom.ign
│ ├── network.ign
│ └── network.bu
├── cu-master3
│ ├── custom.ign
│ ├── network.ign
│ └── network.bu
├── hub-node1
│ ├── custom.ign
│ ├── network.ign
│ └── network.bu
├── hub-node2
│ ├── custom.ign
│ ├── network.ign
│ └── network.bu
├── hub-node3
│ ├── custom.ign
│ ├── network.ign
│ └── network.bu
└── rhcos-4.10.26-x86_64-live.x86_64.isoEach of the node hostname directory will contain the speicifc custom.ign with the specific configuration.
- Building the static networking config:
This is the butane file example , network.bu, for static network configuration:
variant: fcos
version: 1.4.0
storage:
files:
- path: /etc/NetworkManager/system-connections/eno12399.nmconnection
mode: 0600
contents:
inline: |
[connection]
id=eno12399
type=ethernet
interface-name=eno12399
[ipv4]
address1=192.168.43.53/25,192.168.43.1
dns=192.168.34.20;192.168.34.21
dns-search=
may-fail=false
method=manualFor more information on butane file.
- Generating the ignition files from the butane file from previous stage:
podman run --rm --tty --interactive --volume ${PWD}:/pwd:z --workdir /pwd quay.io/coreos/butane:release --pretty --strict --raw /apps/rhcos_image_cache/cu-master3/network.bu > /apps/rhcos_image_cache/cu-master3/network.ignThere are multiple alternatives on how to generate the ignition files from the butane file.
Once the ignition file its generated for the static network config network.ign, we can update the main ignition file custom.ign.
The content of the custom.ign should follow the output:
{
"ignition":{
"config":{
"merge":[
{
"source":"https://192.168.34.41:22623/config/master",
"verification":{
}
}
],
"replace":{
"verification":{
}
}
},
"proxy":{
},
"security":{
"tls":{
"certificateAuthorities":[
{
"source":"data:text/plain;charset=utf-8;base64,LS0tLS1CRUdJTiBDRVJUSUZJQ0FURS0tLS0tCk1JSURFRENDQWZpZ0F3SUJBZ0lJTCtRc09UelZJSzB3RFFZSktvWklodmNOQVFFTEJRQXdKakVTTUJBR0ExVUUKQ3hNSmIzQmxibk5vYVdaME1SQXdEZ1lEVlFRREV3ZHliMjkwTFdOaE1CNFhEVEl5TURrd05qRXhNVGswTVZvWApEVE15TURrd016RXhNVGswTVZvd0pqRVNNQkFHQTFVRUN4TUpiM0JsYm5Ob2FXWjBNUkF3RGdZRFZRUURFd2R5CmIyOTBMV05oTUlJQklqQU5CZ2txaGtpRzl3MEJBUUVGQUFPQ0FROEFNSUlCQ2dLQ0FRRUFvTHRUS0hqZG5IY3cKNVpjdmw4OEczK0N5OTZSWUpDNFVZVlNkTUl2bzVad0dvc1dMdVJSSUJnRTVWcm96WVo0Q1REREltY1MvOENyQwp5TTdoZ0U1N2JxS09Od0dXWWF4TUIvK1Mvb2NrZU1lcG1uQ3JLODRCQjhySzR2ZmYwam8wR2ZBTm84bGJDZjFaCmlFMi9NL0RBcjBtdlk3OHM3elU0MkVMSDdwRndsY1VOUWg3RW1yaVJPK09ERjVRdCtURGp6TzRLQ2wzYVpKUzcKNnlDdXBsTlVLUHhKTlM1Q2t0T1B5NndYaVRoZW92Rm5heU1qNmdnVE43QzdLSFFVcDc3RFpWaWt4ZWtxSGswUwpVK0xhdTdaMXUxOHA5eFh6dXgyV3FqRXFwNXpjcWtiblAyY1MxRlZqSkk1R2Q0TXNRRjlZWnVZNEl2OGp5QUwzClV5emh1cGdTcFFJREFRQUJvMEl3UURBT0JnTlZIUThCQWY4RUJBTUNBcVF3RHdZRFZSMFRBUUgvQkFVd0F3RUIKL3pBZEJnTlZIUTRFRmdRVWtiaE1aZGVBSmpvVjJjV0F3dFh1ZTYvUTkvTXdEUVlKS29aSWh2Y05BUUVMQlFBRApnZ0VCQUJHc2xHdnBBWmwzbCtIQTFvclFhUWdZZ1VpQ2NldHkzS1lEUXN4c2YrTUNTWWRKYnptQllBaGNBZHFyCnJYckxWMXhKeWZZbmlUdjBZTHRweVFUUTlFajZBc1dCak9odXovbnV0MFY0d0lZSEJwRUF3MGtzL1ZxbUIvbDUKc09DeDB0Wi9HSERtcys0SEM2VS9wd2o4TUNYcjd0VWZXRExtdnd0NGFFZ1F3MWtGeG9xOTVSVThkWFowM1pGSgpJUWZHemNEOUNXUEJxcmNUcWVWbXA2T1plM2ppSjBZUCtOZDVJTWFHQTFIY2JYTjJsdTllUVZ1a2E2Q3NwT1JNCmZGeVlrZk05Z0VmQlJHemZzWjM4eFFERVZObU91K1VLTVdMOG1rcHVGQTEyZGw0bVhrTWZrT3doZkxTcXVlRGsKNldEWlNBVStzZlppbVZ3aTVTYnphbU5MMWljPQotLS0tLUVORCBDRVJUSUZJQ0FURS0tLS0tCg==",
"verification":{
}
}
]
}
},
"timeouts":{
},
"version":"3.3.0"
},
"passwd":{
"users": [
{
"groups": [
"sudo"
],
"name": "core",
"passwordHash": "$6$ZKfqCkKlptWXhMuD$qzmD0C11Ym21rOCUMptWW/rze065E/.wccbuetSNfBjcLO0rPptN20n3xZwGnnouE8Zx.Gy2z1oZbBgOa9khA/",
"sshAuthorizedKeys": [
"ssh-ed25519 AAAAC3NzaC1lZDI1NTE5AAAAIBTyHeuQMSFT6Rd2BCkQquTeS+3Pw2d2HaAJdN3+mBr1 kni@services"
]
}
]
},
"storage":{
"files":[
{
"path":"/etc/hostname",
"contents":{
"source":"data:,cu-master3"
},
"mode":420
},
{
"path": "/etc/NetworkManager/system-connections/eno12399.nmconnection",
"contents": {
"compression": "gzip",
"source": "data:;base64,H4sIAAAAAAAC/0yKz8rDIBAH7/ssX/wwf0pC2ScJOSz6CxF0DWoLefvSXlrmNMOsLqvCtZB1o+AZmm0/LAu16wSjHSiKRkEbyi4OnUrC91rD+Rw3Eu8LarVsl97Y22zGwUzDfz/9/QRLXivP5sP9LV2FFHcwJbm6XULkXWIFJbQje06iD4n0CgAA///Ec2TKowAAAA=="
},
"mode": 384
}
]
},
"systemd":{
}
}- Building the customized image for each node:
podman run --privileged -v /apps/rhcos_image_cache/:/data quay.io/coreos/coreos-installer:release iso ignition embed /apps/rhcos-4.10.26-x86_64-live.x86_64.iso -f -i /data/cu-master3/custom.ign -o /data/cu-master3/rhcos-4.10.26-cu-master3.isoThis command will provide the rhcos-4.10.26-cu-master3.iso in the /data/cu-master3/, use the image resulted to mount to the virtualmedia of the server and boot using Virtual CD/DVD/ISO.
NOTE: You can use the command from Step 5.1. Reinstall of the removed node where we are creating a container that exposes the files for fruther use from the Bastion Host.
To achieve this, you can run the following command:
podman run -d --name rhcos_image_cache -v /apps/rhcos_image_cache:/var/www/html -p 9092:8080/tcp quay.io/centos7/httpd-24-centos7:latestOnce the newly added control plane node it has booted with the .iso image, you will be able to ssh into the node by using the coreos user and the sshkey stored into the Bastion Host. Once login to the newly added control plane node, you can run the following command to start the RHCOS installation:
sudo coreos-installer install /dev/sdb --copy-networkIf you are using a multipath root disk over SAN you will need to install the RHCOS:
sudo coreos-installer install /dev/dm-0 --append-karg rd.multipath=default --append-karg root=/dev/disk/by-label/dm-mpath-root --append-karg=rw --copy-networkNOTE: The following parameter flags: --append-karg rd.multipath=default --append-karg root=/dev/disk/by-label/dm-mpath-root --append-karg=rw are emabling the multipath flags in kernel.
Step 6. Approving the new node certificates
- Check if there are newly created certificates pending:
oc get csr- Approve all the pending certificates:
oc get csr -o go-template='\n' | xargs --no-run-if-empty oc adm certificate approveStep 7. Adding the control node back to the cluster
- Create the new BareMetalHost object and the secret to store the BMC credentials:
---
apiVersion: v1
data:
password: Y2Fsdmlu
username: cm9vdA==
kind: Secret
metadata:
name: cu-master3-bmc-secret
namespace: openshift-machine-api
type: Opaque
---
apiVersion: metal3.io/v1alpha1
kind: BareMetalHost
metadata:
name: cu-master3
namespace: openshift-machine-api
annotations:
kubectl.kubernetes.io/last-applied-configuration: |
{"apiVersion":"metal3.io/v1alpha1","kind":"BareMetalHost","metadata":{"annotations":{},"name":"cu-master3","namespace":"openshift-machine-api"},"spec":{"automatedCleaningMode":"metadata","bmc":{"address":"idrac-virtualmedia://192.168.34.232/redfish/v1/Systems/System.Embedded.1","credentialsName":"cu-master3-bmc-secret","disableCertificateVerification":true},"bootMACAddress":"b0:7b:25:d4:59:80","bootMode":"UEFI","online":true}}
spec:
automatedCleaningMode: metadata
bmc:
address: idrac-virtualmedia://192.168.34.232/redfish/v1/Systems/System.Embedded.1
credentialsName: cu-master3-bmc-secret
disableCertificateVerification: true
bootMACAddress: b0:7b:25:d4:59:80
bootMode: UEFI
consumerRef:
apiVersion: machine.openshift.io/v1beta1
kind: Machine
name: cu-compact-1-7znk2-master-3
namespace: openshift-machine-api
customDeploy:
method: install_coreos
externallyProvisioned: true
online: true
userData:
name: master-user-data-managed
namespace: openshift-machine-api- Applying the BareMetalHost object:
oc create -f new-master-bmh.yaml
secret/cu-master3-bmc-secret created
baremetalhost.metal3.io/cu-master3 created- Creating the new Machine object:
---
apiVersion: machine.openshift.io/v1beta1
kind: Machine
metadata:
annotations:
machine.openshift.io/instance-state: externally provisioned
metal3.io/BareMetalHost: openshift-machine-api/cu-master3
finalizers:
- machine.machine.openshift.io
generation: 3
labels:
machine.openshift.io/cluster-api-cluster: cu-compact-1-7znk2
machine.openshift.io/cluster-api-machine-role: master
machine.openshift.io/cluster-api-machine-type: master
name: cu-compact-1-7znk2-master-2
namespace: openshift-machine-api
spec:
metadata: {}
providerSpec:
value:
apiVersion: baremetal.cluster.k8s.io/v1alpha1
customDeploy:
method: install_coreos
hostSelector: {}
image:
checksum: ""
url: ""
kind: BareMetalMachineProviderSpec
metadata:
creationTimestamp: null
userData:
name: master-user-data-managed
status:
addresses:
- address: ""
type: InternalIP
- address: 192.168.34.53
type: InternalIP
- address: ""
type: InternalIP
- address: ""
type: InternalIP
nodeRef:
kind: Node
name: cu-master3- Checking the nodes in the cluster:
NAME STATUS ROLES AGE VERSION
cu-master1 Ready master 9h v1.23.5+012e945
cu-master2 Ready master 9h v1.23.5+012e945
cu-master3 Ready master 4h29m v1.23.5+012e945
hub-node1 Ready worker 9h v1.23.5+012e945
hub-node2 Ready worker 9h v1.23.5+012e945
hub-node3 Ready worker 9h v1.23.5+012e945